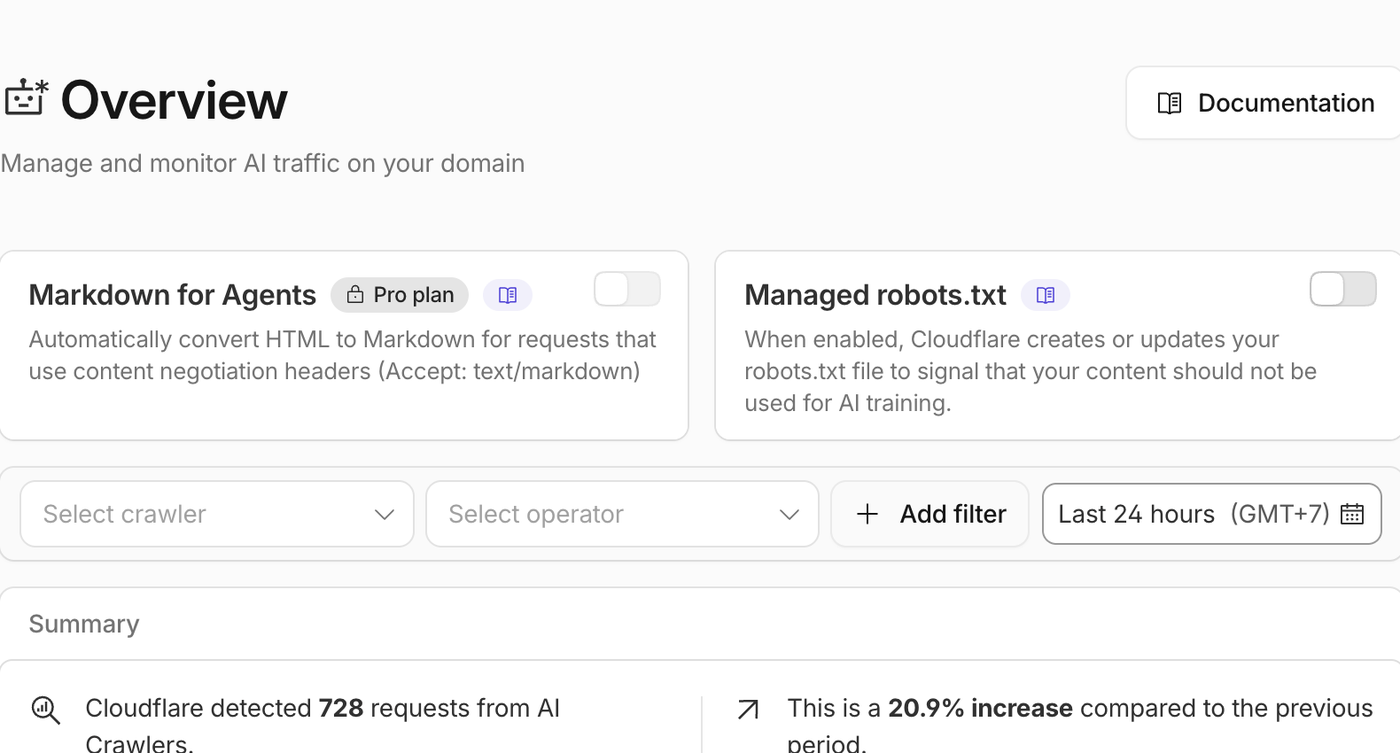
Cloudflare is often treated as just a CDN, but for SEO it can do much more than cache static files. Once a website is behind Cloudflare, requests pass through Cloudflare before they reach the origin server. That gives site owners practical control over speed, HTTPS, caching, redirects, bot access, security, and even AI crawler visibility.
Category: AI SEO
-

How I Helped a Client Fix AI Crawlers Blocked by Cloudflare
Want to check your own site? I built a free AI Crawler & llms.txt Checker that tests
(more…)llms.txt,llms-full.txt,robots.txt, AI crawler user agents, and the links inside the file.
