In March 2026, Materacyk.pl — a Polish online shop selling kids’ and baby mattresses — was earning just over 1,000 organic visits a month. Four months later it was down to 91. No manual penalty, no core-update casualty story, and the domain’s authority (DR 19) never moved. The cause turned out to be almost embarrassingly mechanical: after a site migration, 44 old ranking URLs were redirected to one generic product-listing page.
This post is a teardown of the actual recovery proposal I sent that client, published with the real numbers intact. It is a working example of SEO traffic recovery done in the right order: diagnose the loss, fix what broke, and only then spend money on new growth. If you write proposals yourself — or you are trying to judge one you received — read it as a template. It follows the same logic as my SEO recovery plan framework, applied to a live e-commerce case.
TL;DR
- After a site migration, 44 old ranking URLs were 301-redirected to one generic product-list page instead of their true equivalents.
- Google reads those mis-redirects as soft 404s and drops the pages — organic traffic fell about 90% (roughly 950 to 91 visits a month).
- The fix comes first (Week 0): repoint each URL to its real match, restore the removed articles, and 410 the one discontinued line — recovering about 455 visits a month plus the site’s link equity.
- Only then spend on new growth: keyword research, on-page SEO, and link building.
The collapse: from ~950 visits a month to 91
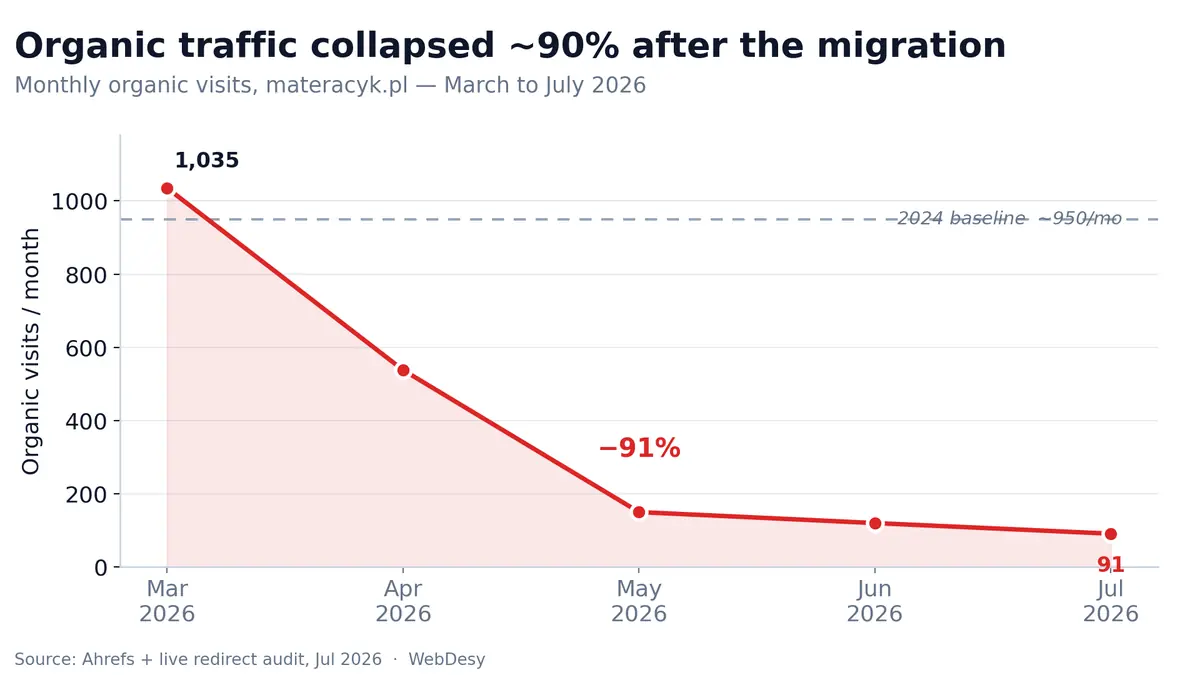
The store’s organic traffic had been stable at roughly 950 visits a month through 2024. Then, from March 2026, it fell off a cliff:
- March 2026 — 1,035 visits
- April 2026 — 538 visits
- May 2026 — 150 visits
- June 2026 — 120 visits
- July 2026 — 91 visits
By July the site ranked for only about 7 keywords, almost all brand terms. Here is the detail that pointed to the diagnosis: nothing else degraded. The backlink profile stayed put, and Domain Rating held at 19. When authority stays intact while rankings vanish within weeks, the first suspect is not content quality or links — it is something mechanical, and a recent migration is the usual crime scene.
The diagnosis: 44 ranking URLs, one generic landing page
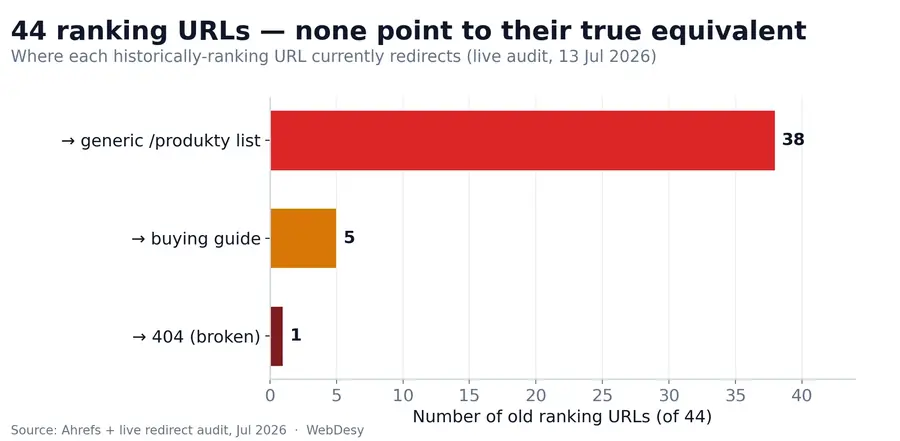
A live audit of every historically ranking URL (re-confirmed 13 July 2026) found that of the 44 old URLs that used to earn organic traffic:
- 38 redirect to the generic
/produktyproduct list — not to their equivalent product, category or article; - 5 redirect to the buying guide, a loosely related page at best;
- 1 is an outright 404.
Not a single one pointed to its true equivalent on the new site.
Why Google reads these as soft 404s
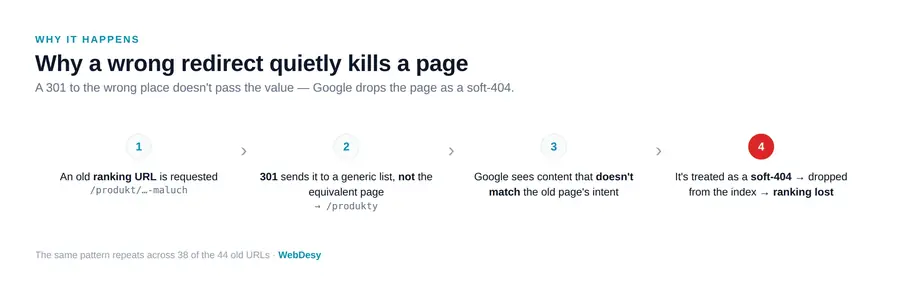

A 301 redirect only transfers rankings and link equity when the destination genuinely replaces the old page. Google evaluates the target: if a crib-mattress product URL, a “which mattress for a 3-year-old” guide and a sheets category all land on the same generic listing page, none of those targets answers the original query. Google treats each of those redirects like the content is simply gone — a soft 404, as described in Google’s own crawling documentation — and drops the old URL from the index. Multiply that by 38 and you get exactly the traffic curve above.
Two implementation details make or break this. First, use permanent 301 redirects, not temporary 302s — a 302 tells Google the move is temporary, so it keeps the old URL indexed and withholds the ranking signals from the new page. Second, make sure each destination’s canonical tag points to itself, not back to an old URL, or you quietly re-create the same problem.
Two assets were quietly being wasted
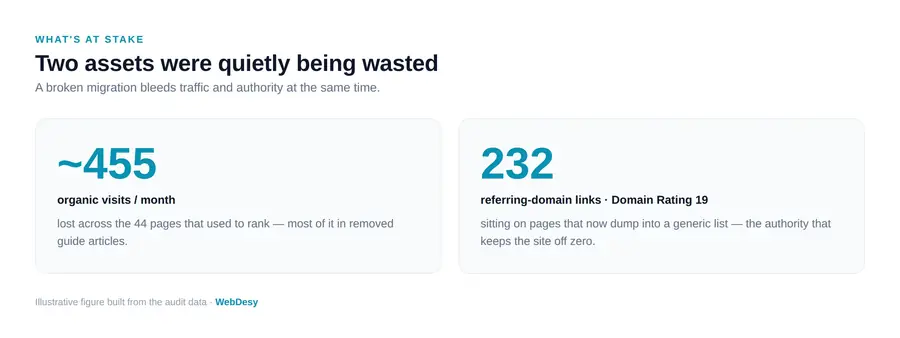
The broken redirects were burning two different things at once, and separating them is what shaped the whole plan.
1. The traffic the pages used to earn. One year before the collapse, those 44 URLs were bringing in roughly 455 organic visits a month between them. That is recoverable demand — people still search for these things every month.
2. The link equity keeping the domain alive. Backlinks earned over years still point at the old URLs. The single most-linked page — the bezpieczny maluch crib mattress product — has 102 referring domains pointing at it, and all of that authority currently dumps into the generic /produkty list. This is what keeps the site at DR 19 instead of 0, and it is the more valuable asset: rankings can be rebuilt, but years of naturally earned links cannot be cheaply replaced.
Here is the full list of link-bearing pages — the centerpiece of the proposal. Almost every row mis-redirects today:
| Old URL (materacyk.pl) | Ref. domains | Redirects to today | Should point to |
|---|---|---|---|
| /produkt/materac-do-lozeczka-bezpieczny-maluch | 102 | /produkty ✗ | /kategoria/materace-dla-niemowlat-0-3 |
| /produkt/materac-lateksowy-antyalergic-covers-model-ml1 | 27 | /produkty ✗ | /produkty/sensitive |
| /produkt/materac-sensitive-dla-dzieci | 19 | /produkty ✗ | /produkty/sensitive |
| /produkt/materac-lateksowy-sensitive | 15 | /produkty ✗ | /produkty/sensitive |
| ⭐ /sklep/materace-dla-dzieci | 14 | /produkty ✗ | /kategoria/materace-dla-dzieci-4-18 |
| /produkt/materac-lateksowy | 12 | /produkty ✗ | /produkty/sensitive |
| /produkt/materac-sensitive-model-ms11 | 9 | /produkty ✗ | /produkty/sensitive |
| /produkt/materac-dzieciecy-odeo-model-mohrpur1 | 8 | /produkty ✗ | /produkty/materac-wysokoelastyczny-vera-3 |
| /materace-dla-dzieci-html | 5 | 404 (broken) ✗ | /kategoria/materace-dla-dzieci-4-18 |
| /produkt/materac-dzieciecy-odeo-plus | 5 | /produkty ✗ | /produkty/materac-wysokoelastyczny-vera-3 |
| /produkt/poduszka-fikuszka | 5 | /produkty ✗ | /kategoria/poduszki |
| /produkt/poduszka-gniazdko | 5 | /produkty ✗ | /produkty/poduszka-gniazdko-lemon-tree-green-fm47 |
| /produkt/poduszka-relaksacyjna-z-nadrukiem-fp3-fikuszka-kolekcja-lemon-tree | 2 | /produkty ✗ | /produkty/poduszka-gniazdko-lemon-tree-green-fm47 |
| /produkt/wyrob-medyczny-kl-fikusna-poduszka | 2 | /produkty ✗ | /kategoria/poduszki |
| /sklep/dodatki/dla-kobiet-w-ciazy | 2 | /produkty ✗ | /kategoria/poduszki-dla-kobiet-w-ciazy |
Traffic dropped after a migration or redesign?
Get a free redirect audit — I will map every old ranking URL to its true equivalent and show you what a recovery-first fix would cover, or read the step-by-step SEO workflow I follow.
The table sums to 232 referring-domain links across 15 pages (page-level Ahrefs counts, so a domain linking to several pages is counted per page). The domain’s live total is 452 referring domains, 1,979 all-time. Every page with two or more referring domains is included. ⭐ marks pages that carry both traffic and backlinks — the do-first rows.
What happens to each of the 44 URLs
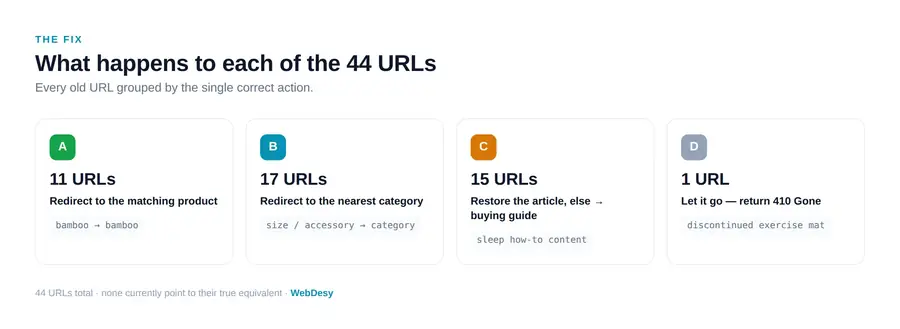
Grouping the 44 pages by the correct action is what turns a diagnosis into an implementation file. The full old-to-new redirect map — every URL with its exact target and redirect type, ready for the developer — ships as the Week 0 deliverable. Here is the logic per group, with a sample of each.
A. Redirect to the matching product — 11 URLs
The old item still has an equivalent product on the new site, so the redirect is one-to-one. Examples: the bamboo foam mattress page (20 visits/mo a year before the collapse) goes to the same product’s new URL; the ⭐ latex Sensitive mattress (10 visits/mo) goes to /produkty/sensitive; the ⭐ Odeo Plus kids’ mattress maps to its successor model, Vera 3.
B. Redirect to the nearest category — 17 URLs
Old size pages, shop categories and accessories with no one-to-one product; the closest category is the right target. The single biggest traffic loser on the whole site sits here: /jaki-materac-dla-3-latka/ (“which mattress for a 3-year-old”) earned 131 visits/mo and now dumps into the generic list — it should point to the kids’ 4–18 mattress category. Size pages like 140×70 and 120×60 map to the baby 0–3 category; pillow and bedding accessories map to their real categories.
C. Restore the article — or redirect to the buying guide — 15 URLs
Sleep-advice content carried most of the lost ~455 visits/mo: “when to lower the crib” (49 visits/mo), “what should a newborn sleep in” (43), “what is REM sleep” (32), and a dozen more. A redirect to the buying guide preserves some value, but restoring the articles recovers the most — this content earned links and answered real parent questions. Restore where the original content is recoverable; redirect the rest.
D. Let it go: 410 Gone — 1 URL
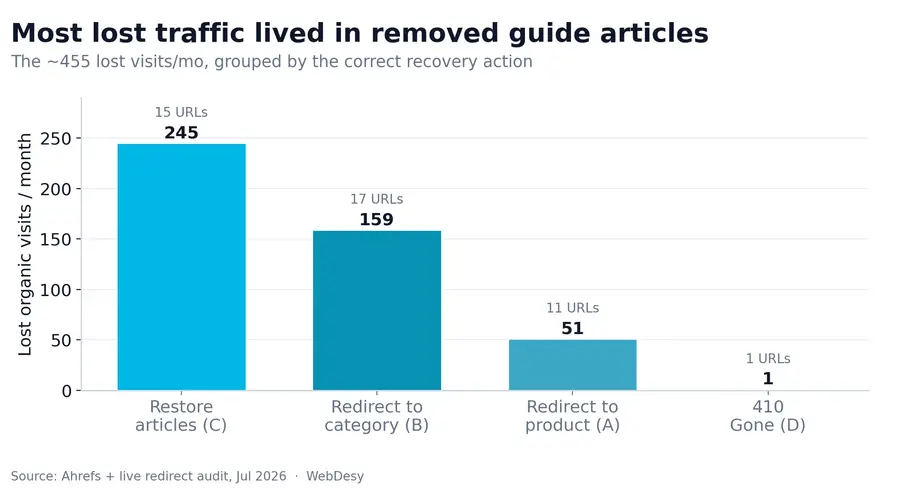
One discontinued line (an exercise mat) has no equivalent on the new site. Redirecting it to something unrelated would create yet another soft 404, so it returns HTTP 410 — a deliberate “gone” that cleans it out of the index. (If the line ever comes back, restock the page instead.)
The week-by-week SEO traffic recovery plan (with real prices)
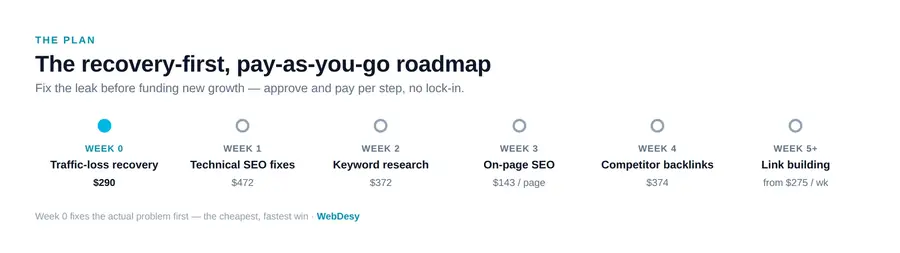
The plan is pay-as-you-go: each step is a standalone deliverable the client approves and pays for separately — no lock-in retainer. It deliberately starts with recovery, because reclaiming ~455 visits/mo through redirect fixes is far cheaper than buying the same traffic back with new content and links. The structure mirrors the three-step SEO workflow I use on every project, with a Week 0 bolted on front.
| Step | What happens | Price |
|---|---|---|
| Week 0 | Traffic-loss recovery: fix all 44 redirects, restore or 410, re-submit sitemap | $290 (≈ 1,100 PLN) |
| Week 1 | Technical SEO — issues fixed where the CMS allows, not just reported | $472 (≈ 1,795 PLN) |
| Week 2 | Keyword research mapped to the store’s category tree | $372 (≈ 1,415 PLN) |
| Week 3 | On-page SEO for the categories with the highest sales potential | $143 per page (≈ 545 PLN) |
| Week 4 | Competitor backlink analysis for the Polish baby-mattress niche | $374 (≈ 1,420 PLN) |
| Week 5+ | Link building per the Week 4 evidence — editorial, dofollow, no PBNs | from $275/week (≈ 1,045 PLN) |
Weeks 0–4 total about $1,508 (≈ 5,730 PLN) one-off, at roughly 3.80 PLN to the dollar. Week 0 alone — the fix for the actual problem — is $290.
Week 0 runs in strict priority order: reconcile the list against the client’s own Search Console and Analytics first (tool estimates are a map, not the territory); repoint the link-bearing pages to protect DR 19; hit the ⭐ double-win pages on day one; then the traffic pages, then restore the guides, then accessories; 410 the one discontinued line; finish by re-submitting the sitemap and requesting re-indexing.
The later weeks are standard but sequenced on purpose: technical fixes come before new issues can pile up again, keyword research in Ahrefs decides which categories deserve on-page investment, and link building starts only after the competitor analysis proves what the niche actually requires — because backlinks alone will not fix traffic loss when the underlying redirects are broken.
Expected outcome: the redirect fix protects the site’s authority immediately, and the lost visits should begin returning within roughly 4–8 weeks of re-indexing. That window is an expectation based on how Google re-crawls corrected redirects — stated in the proposal explicitly as an expectation, not a guarantee.
Verified vs. inferred: label your evidence
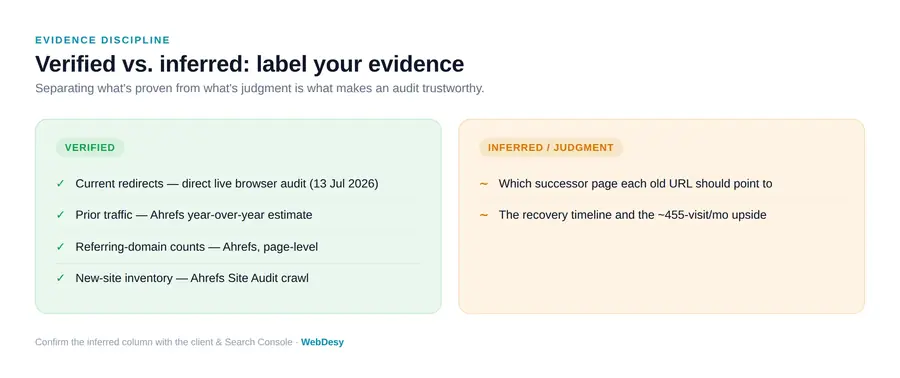
The section of the proposal I would most encourage anyone to steal is the method note that separates what was verified from what was inferred:
- Current redirects — verified. Every one of the 44 old URLs was checked in a live browser audit, re-confirmed 13 July 2026 (38 →
/produkty, 5 → guide, 1 → 404). - Prior traffic — modelled estimate. Ahrefs year-over-year figures (each page’s visits/mo one year before the collapse), re-pulled row-by-row — and labelled as estimates to be reconciled against the client’s Search Console in Week 0.
- Link counts — methodology stated. 232 referring-domain links across 15 pages are page-level counts (a domain linking to three pages counts three times); the domain-level total is 452 unique referring domains.
- Crawler limits — acknowledged. A site-audit crawler only reaches internally linked pages, so it cannot see these orphaned dead URLs at all; it was used only to inventory the new site’s real categories and products.
- Recommended targets — judgment. Which successor page each URL should point to is a proposal to confirm page-by-page with the client, not verified fact.
This one habit — grading your own evidence — does more for client trust than any promise. It also happens to be exactly what separates a recovery plan from a sales pitch.
What makes a recovery-first proposal different

- Recovery before growth. The traffic collapse gets fixed before a single dollar goes to new content or links.
- Fixes, not just reports. Technical findings are implemented where the CMS allows, not handed over as a PDF.
- An evidence-based, niche-specific link plan — not a fixed monthly link quota invented before anyone looked at the competitors.
- A quality floor on links, in writing. No directories, PBNs, link farms or sitewide footers.
- Pay per step, approve as you go. No indefinite retainer, no risk of paying for thin work.
The proposal also flags its own cost drivers up front: technical and on-page scope depends on how flexible the CMS turns out to be (confirmed in Week 1), and the link-building price is a placeholder until Week 4 produces real numbers. Clients respond well to being told where the uncertainty lives.
FAQ
Why do redirects to a generic page cause traffic loss?
Google checks whether a redirect target actually replaces the old page. When dozens of different product and article URLs all land on one generic listing page, the target does not answer the original query, so Google treats each redirect as a soft 404 and drops the old page’s rankings. The traffic those pages earned disappears instead of transferring to the new site.
What is a soft 404?
A soft 404 is a URL that returns a success response, or a redirect, while behaving like a missing page — an empty result, an error message, or a substitute page that does not match what the URL used to contain. Google flags these in Search Console and drops them from the index, because from the searcher’s point of view the content is gone.
How long does SEO traffic recovery take after fixing redirects?
Expect roughly 4 to 8 weeks after the corrected redirects are re-crawled: Google has to revisit each old URL, follow the new 301, and re-associate the accumulated signals with the correct target. Re-submitting the sitemap and requesting re-indexing in Search Console speeds this up. That timeline is an expectation based on how Google re-crawls corrected redirects, not a guarantee.
When should you use a 410 instead of a 301?
Use a 301 when a genuinely equivalent page exists, such as the matching product or the closest relevant category. Use a 410 (Gone) when the content is discontinued and nothing on the site truly replaces it — redirecting it to an unrelated page would just create another soft 404. In this plan, 43 of the 44 URLs get a 301 or a restored page, and one discontinued product line gets a 410.
What is recovery-first SEO?
Recovery-first SEO means fixing whatever destroyed existing traffic before spending anything on new growth. Reclaiming rankings a site already earned — through corrected redirects, restored pages and recovered link equity — is cheaper and faster than building new visibility from scratch, so it becomes Week 0 of the plan, and keyword research, on-page work and link building then build on the recovered baseline.
The takeaway
If your organic traffic collapsed shortly after a migration or redesign, audit your old URLs before you buy anything: pull the pages that used to rank, follow every redirect, and ask of each one — does this land on a true equivalent? A store that loses 90% of its traffic to mis-mapped redirects does not need more content or more links first. It needs Week 0. If you would like a second pair of eyes on a collapse like this one, get in touch.
Proposal prepared by Vitalii Kolos for Materacyk.pl, 13 July 2026; published as an educational teardown with the client’s data as analysed at that date. Traffic figures are Ahrefs estimates unless noted; the redirect map assumes the new site’s URLs stay where they are today.